
Mastering theMolecular Basis of Inheritance NEET is the difference between guessing and scoring 360/360. If you’ve finished our 500 MCQ challenge, it’s time to stop memorizing facts and start understanding the ‘Why’ behind every DNA strand.
🧬 DNA Replication: The Semi-Conservative Model
In NEET, questions often focus on the direction of synthesis and the enzymes involved. Here is the breakdown you need:
Key Enzymes & Their Roles
| Enzyme | Function |
| Helicase | Unwinds the DNA double helix (The “Unzipper”). |
| SSB Proteins | Stabilize the single strands to prevent re-annealing. |
| Primase | Synthesizes a short RNA primer to start the process. |
| DNA Polymerase III | Adds nucleotides in the 5′ – 3′ direction. |
| Ligase | Joins the Okazaki fragments on the lagging strand. |
🔹 Introduction to DNA & Genetic Information
📚 Table of Contents: DNA to Protein
🔹 DNA Packaging
- Length of DNA vs Nuclear Size
- Nucleosome (Basic Unit)
- Histone Octamer
- Linker DNA
- Beads-on-a-String Structure
- Chromatin to Chromosome
🔹 Search for Genetic Material
🔹 Central Dogma of Molecular Biology
🔹 DNA Replication
🔹 Transcription (DNA → RNA)
- Transcription Unit
- Template vs Coding Strand
- Steps of Transcription
- Eukaryotic Transcription (Exons & Introns)
🔹 Translation (RNA → Protein)
🔹 Genetic Code
🧬 DNA
DNA is something very important inside your body. You cannot see it with your eyes, but it is present in almost every cell of your body. It works like a secret instruction book that tells your body how to grow, how to look, and how to function properly. For example, the reason why your eyes are black or brown, your hair is straight or curly, or your height is tall or short — all of this information is already written in your DNA.
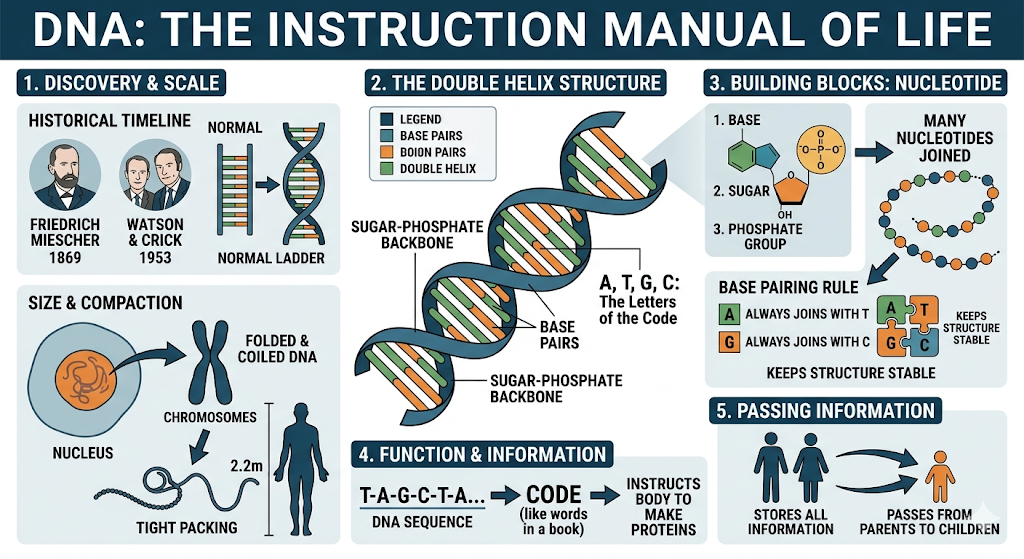
A long time ago, a scientist named Friedrich Miescher discovered DNA in 1869, but he did not fully understand it. Later, in 1953, two scientists, James Watson and Francis Crick, explained its structure. They found that DNA looks like a twisted ladder, which is called a double helix. Imagine a normal ladder, and then twist it — that is how DNA looks inside your body.
DNA is not a single solid thing. It is made up of many very small units joined together, just like beads in a necklace. These small units are called nucleotides. Each nucleotide has three parts — a base, a sugar, and a phosphate group. When many nucleotides join together, they form a long chain. Two such chains come together and twist to form the DNA structure.
In DNA, there are only four types of bases, which you can think of as letters. These are A, T, G, and C. These letters join in a very specific way. A always joins with T, and G always joins with C. They never change partners. Because of this pairing, the DNA structure remains stable and organized.
The sides of the DNA ladder are made of sugar and phosphate, while the middle steps are formed by these base pairs (A–T and G–C). This structure helps DNA store information in a proper way. The sequence of these letters (A, T, G, C) acts like a code, just like words in a book. This code tells the body what proteins to make, and proteins are responsible for all activities in the body.
Another amazing thing about DNA is its length. If you take out all the DNA from a single cell, it would be about 2.2 meters long, which is much longer than your height! But it is packed very tightly inside a very tiny space in the cell. This is possible because DNA is folded and coiled in a special way.
In simple words, DNA is the instruction manual of life. It stores all the information needed for life and passes it from parents to children. Without DNA, no living organism can grow, survive, or reproduce.
🧬 DNA Packaging
Inside our body, DNA is extremely long. If we stretch the DNA from just one cell, it will be about 2.2 meters long, which is even longer than our height! But the surprising thing is that this long DNA fits inside a very tiny nucleus, which is only about 10−610^{-6}10−6 meters wide. So the question is, how does such a long DNA fit into such a small space?
The answer is DNA packaging. The DNA does not remain straight. It is carefully folded, coiled, and packed in a very organized way so that it can fit inside the nucleus without getting tangled.
The most basic level of DNA packaging is called a nucleosome. You can imagine it like a thread wrapped around small balls. In this case, the DNA acts like the thread, and it wraps around special proteins called histones. This structure forms a unit known as a nucleosome.
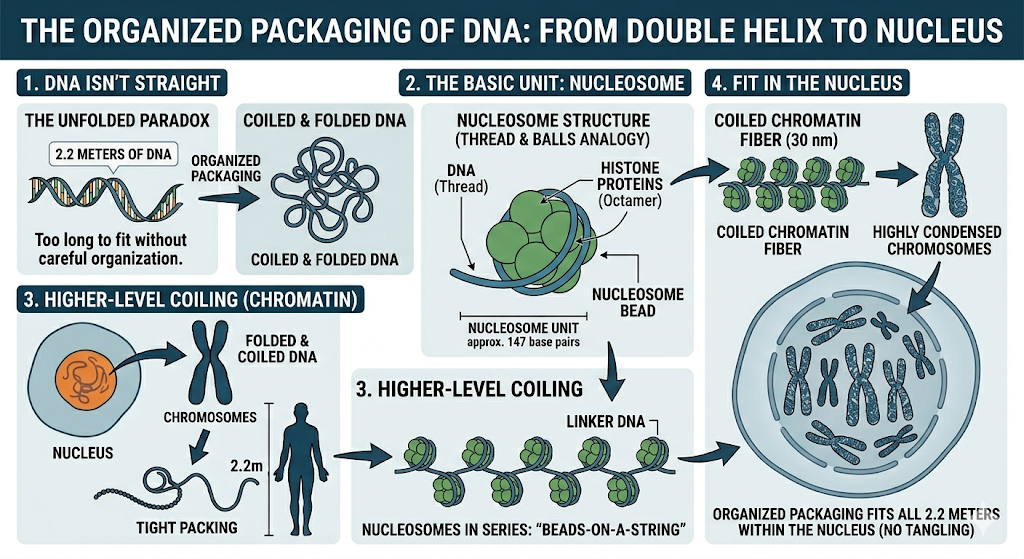
Each nucleosome contains a group of proteins called a histone octamer. The word “octamer” means eight, so a histone octamer is made up of eight histone proteins. DNA wraps around this group of eight proteins like a ribbon around a spool. This wrapping helps in shortening the length of DNA.
Between two nucleosomes, there is a small stretch of DNA that is not wrapped around histones. This part is called linker DNA. It connects one nucleosome to another, just like a string connecting beads.
When many nucleosomes are arranged in a row, the structure looks like beads on a string. Here, the beads are nucleosomes and the string is the DNA. This is the first visible level of DNA packaging.
But the packing does not stop here. This “beads-on-a-string” structure further coils and folds again and again to form thicker fibers. These fibers become even more tightly packed to form chromatin, which is a complex of DNA and proteins.
Finally, during cell division, this chromatin becomes highly condensed and forms visible structures called chromosomes. These chromosomes carry all the genetic information needed for the cell.
In simple words, DNA goes through many levels of folding:
first forming nucleosomes, then a beads-on-a-string structure, then chromatin, and finally chromosomes. This step-by-step packing allows a very long DNA molecule to fit inside a tiny nucleus in an organized way.
Griffith Experiment (1928)
The Frederick Griffith experiment (1928) demonstrated how genetic information can be transferred between organisms. He used the bacterium Streptococcus pneumoniae, which exists in two forms: the smooth (S-type), which is virulent and has a protective capsule, and the rough (R-type), which is non-virulent and lacks a capsule. This difference allowed him to study how bacteria cause disease.
In his experiment, Griffith injected mice with different combinations of bacteria. Mice injected with live S-type bacteria died, while those injected with live R-type bacteria survived. When heat-killed S-type bacteria were injected, the mice remained alive. However, when heat-killed S-type bacteria were mixed with live R-type bacteria and injected, the mice died. Interestingly, live S-type bacteria were recovered from the dead mice, even though only dead S-type bacteria were initially used.
From these results, Griffith concluded that some substance from the dead S-type bacteria transformed the harmless R-type bacteria into virulent S-type bacteria. He called this substance the “transforming principle.” Later, scientists Oswald Avery, Colin MacLeod, and Maclyn McCarty proved that this transforming principle is DNA, establishing DNA as the genetic material responsible for heredity.
Avery, MacLeod & McCarty Experiment
The experiment conducted by Oswald Avery, Colin MacLeod, and Maclyn McCarty in 1944 identified the true nature of the “transforming principle” first observed in Frederick Griffith’s experiment. They worked with the bacterium Streptococcus pneumoniae to determine which biomolecule—protein, RNA, or DNA—was responsible for transformation.
In their experiment, they took heat-killed virulent (S-type) bacteria and removed different components using specific enzymes. When proteins were destroyed using protease and RNA was destroyed using RNase, transformation still occurred, meaning R-type bacteria were converted into S-type. However, when DNA was destroyed using DNase, transformation did not occur, and the R-type bacteria remained non-virulent.
From these observations, they concluded that DNA is the transforming principle and is responsible for carrying genetic information. This experiment provided strong evidence that DNA, not protein or RNA, is the genetic material, laying the foundation for modern molecular biology.
Key Enzymes in DNA Replication
DNA replication is a complex process that involves several important enzymes working together to copy genetic material accurately. One of the main enzymes is DNA helicase, which unwinds the double helix by breaking hydrogen bonds between the two strands. This creates a replication fork and exposes the template strands for copying. Another important enzyme is DNA gyrase (a type of topoisomerase), which prevents the DNA from becoming too tightly coiled during unwinding.
DNA polymerase plays a central role in replication by adding new nucleotides to the growing DNA strand in a complementary manner. It can only add nucleotides in the 5′ to 3′ direction and also has a proofreading function to correct errors. Since DNA polymerase cannot start synthesis on its own, primase first synthesizes a short RNA primer that provides a starting point. These primers are later removed and replaced with DNA.
Finally, DNA ligase joins the Okazaki fragments on the lagging strand by sealing the gaps between them, forming a continuous strand. In addition, enzymes like exonuclease help remove RNA primers and incorrect nucleotides. Together, these enzymes ensure that DNA replication is accurate and efficient, allowing genetic information to be passed correctly from one cell to another.
Transcription (DNA → RNA)
Transcription is the process by which genetic information stored in DNA is copied into RNA. This process is essential for protein synthesis, as RNA carries the code from DNA to the ribosome. It mainly occurs in the nucleus of eukaryotic cells and is carried out by the enzyme RNA polymerase.
Transcription Unit
A transcription unit is a segment of DNA that is transcribed into RNA. It has three main parts:
- Promoter: The starting point where RNA polymerase binds
- Structural gene: The DNA sequence that is transcribed
- Terminator: The signal where transcription stops
These components ensure that transcription starts and ends at the correct positions.
Template vs Coding Strand
During transcription, only one strand of DNA is used as a template:
- Template strand: The strand that is actually read by RNA polymerase to synthesize RNA
- Coding strand: The strand that has the same sequence as the RNA (except thymine is replaced by uracil)
So, RNA is complementary to the template strand and similar to the coding strand.
Steps of Transcription
Transcription occurs in three main steps:
- Initiation: RNA polymerase binds to the promoter and unwinds the DNA
- Elongation: RNA nucleotides are added one by one to form the RNA strand
- Termination: RNA polymerase reaches the terminator and releases the newly formed RNA
Eukaryotic Transcription (Exons & Introns)
In eukaryotic cells, transcription is more complex. The initial RNA formed is called primary RNA (hnRNA), which contains both exons (coding regions) and introns (non-coding regions). Before becoming functional, introns are removed and exons are joined together in a process called splicing. The final processed RNA is called mRNA, which is then used for protein synthesis.
🔹Translation (RNA → Protein)
Translation is the process by which the genetic code present in RNA is used to synthesize proteins. It occurs in the cytoplasm on ribosomes, where the sequence of nucleotides in mRNA is translated into a sequence of amino acids to form a protein.
Role of mRNA
Messenger RNA (mRNA) carries genetic information from DNA to the ribosome. It contains codons (groups of three nucleotides), and each codon specifies a particular amino acid. The sequence of codons in mRNA determines the sequence of amino acids in the protein.
tRNA (Adapter Molecule)
Transfer RNA (tRNA) acts as an adapter molecule. It has two important sites:
- Anticodon: A sequence of three nucleotides that pairs with the codon on mRNA
- Amino acid attachment site: Where a specific amino acid is attached
Each tRNA brings the correct amino acid to the ribosome according to the mRNA codon.
Ribosome Function
The ribosome is the site of protein synthesis. It reads the mRNA and provides a platform for tRNA binding. It also catalyzes the formation of peptide bonds between amino acids, helping to build the protein chain.
Steps of Translation
Translation occurs in three main steps:
- Initiation: The ribosome attaches to mRNA and the first tRNA binds to the start codon (AUG)
- Elongation: tRNA molecules bring amino acids one by one, and peptide bonds form between them, elongating the chain
- Termination: When a stop codon is reached, the process stops and the completed protein is released
🔹 Genetic Code
The genetic code is the set of rules by which the information stored in DNA or mRNA is translated into proteins. It consists of codons, which are sequences of three nucleotides, and each codon specifies a particular amino acid. For example, AUG codes for methionine and also acts as the start codon. The genetic code ensures that the correct sequence of amino acids is formed during protein synthesis.
🔹 Properties of Genetic Code
The genetic code has several important properties. It is a triplet code, meaning each codon is made of three nucleotides. It is unambiguous, as each codon codes for only one amino acid. It is also non-overlapping, meaning one nucleotide is part of only one codon, and comma-less, as codons are read continuously without any gaps. Additionally, the code has start codons (like AUG) and stop codons (UAA, UAG, UGA) that signal the beginning and end of protein synthesis.
Universal Nature
The genetic code is said to be universal because the same codons specify the same amino acids in almost all organisms, from bacteria to humans. This shows that all living organisms share a common evolutionary origin. However, there are a few minor exceptions found in some mitochondria and microorganisms.
Degeneracy
Degeneracy of the genetic code means that more than one codon can code for the same amino acid. For example, the amino acid leucine is coded by multiple codons. This redundancy provides stability to the genetic system, as a change in one nucleotide may not always change the amino acid, thus reducing the effect of mutations.
🔗 Explore More NEET -500 MCQs Challenge –
- Evolution
- Breathing and Exchange of Gases
- Anatomy of Flowering Plants
- Body Fluids and Circulation
- Human Health and Disease
- Microbes in Human Welfare
- Cell Cycle and Cell Division
- Biotechnology and Its Applications
- Biodiversity and Conservation
- Morphology of Flowering Plants
Want to strengthen your NEET preparation on NEET Strategies For Enhancement in Food Production?
Click the link below to access more high-quality MCQs from an external source:
👉 Practice More NEET MCQs – External Resource
Credit: External content sourced for educational support. All rights belong to the original author/website.
Class-wise Solutions
Class 12:
Class 12 Physics – NCERT Solutions
Class 12 Chemistry – NCERT Solutions
Class 11:
- Class 11 Physics – NCERT Solutions
- Class 11 Chemistry – NCERT Solutions
- Class 11 Biology – NCERT Solutions
- Class 11 Math – NCERT Solutions
Class 10:
Class 9:
Class 8:
Class 7:
Class 6:
Subject-wise Solutions
Physics:
Chemistry:
Biology:
Math:
- Class 11 Math – NCERT Solutions
- Class 10 Math – NCERT Solutions
- Class 9 Math – NCERT Solutions
- Class 8 Math – NCERT Solutions
Science: